One system for how your spend actually works
Connect your commercial truth to operational reality. AI Teams audit and act; you set the guardrails in Studio.


Trusted by global leaders in Logistics, Manufacturing, and Retail

























Built for real-world spend
Freight is where we started — dense contracts, messy invoices, real money on the line. The same architecture applies wherever spend hides in documents and exceptions.
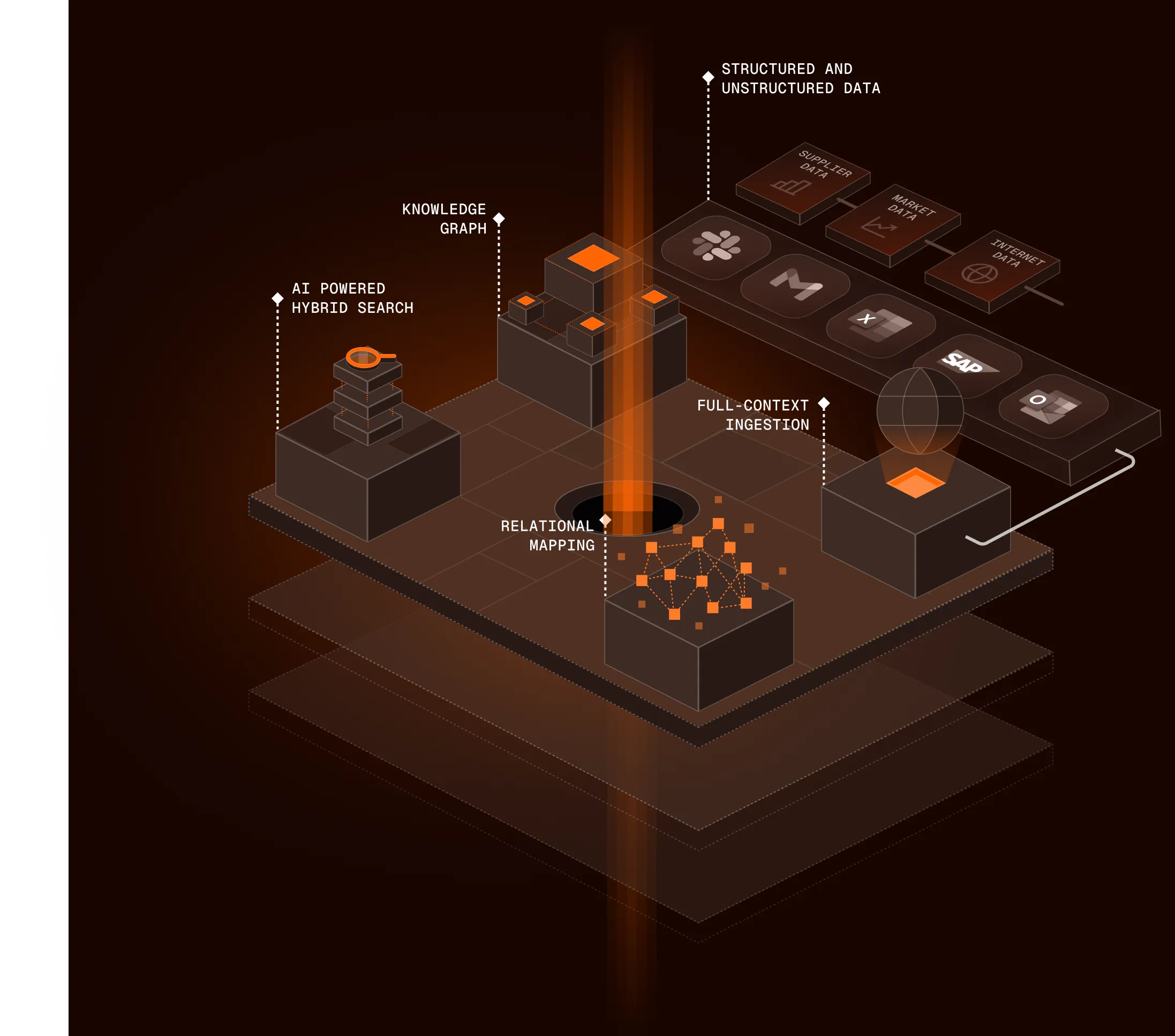
Your spend in context - not in silos
We unify what’s in your ERP, what’s in your contracts, and what happened in execution. Agents don’t guess; they work from the relationships between lanes, rates, shipments, and invoices.



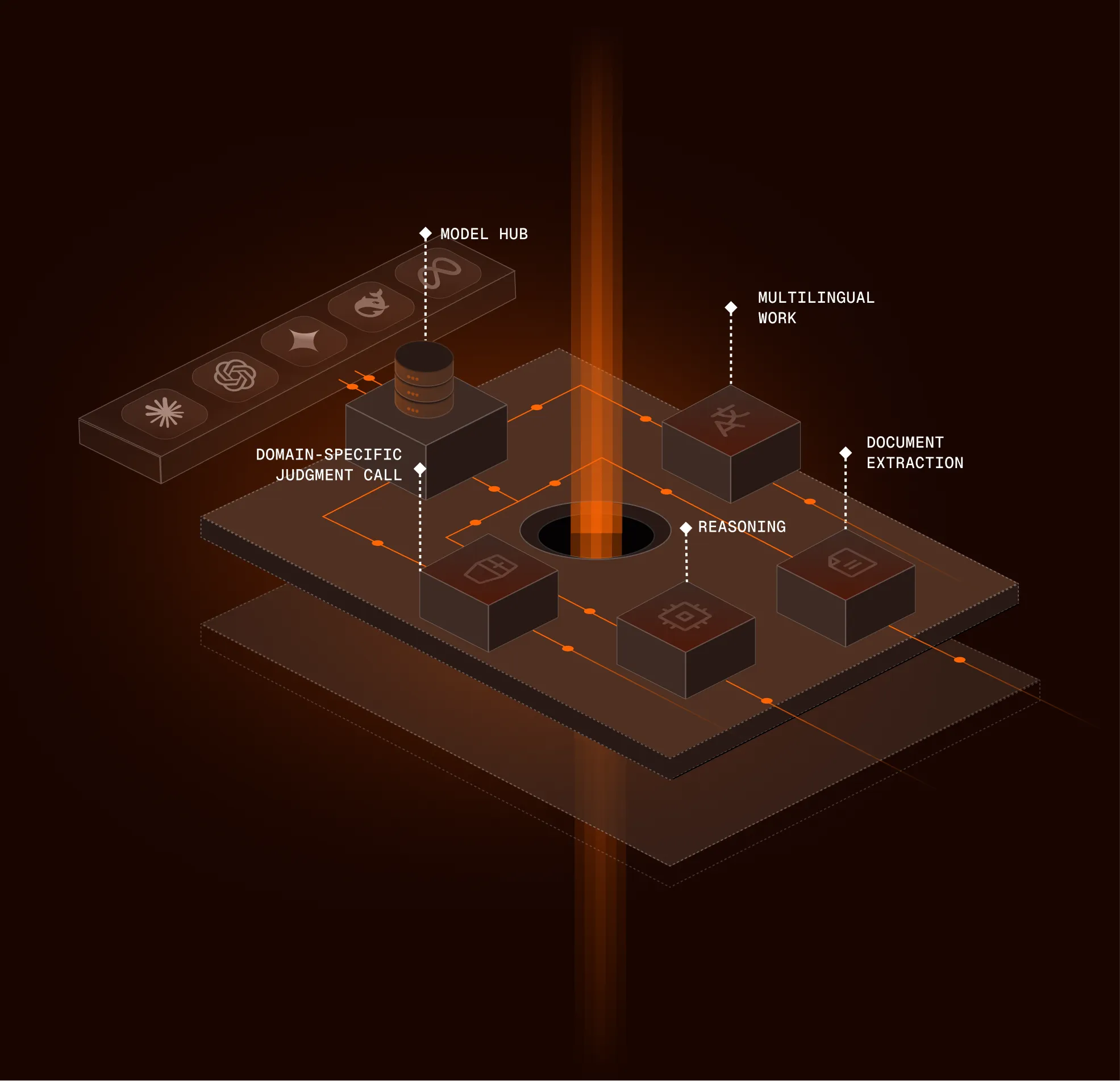
The right model for the job
Different tasks need different capabilities — extraction, judgment, negotiation support. We route work accordingly and keep outputs tied to what’s in your graph, not generic training chatter.
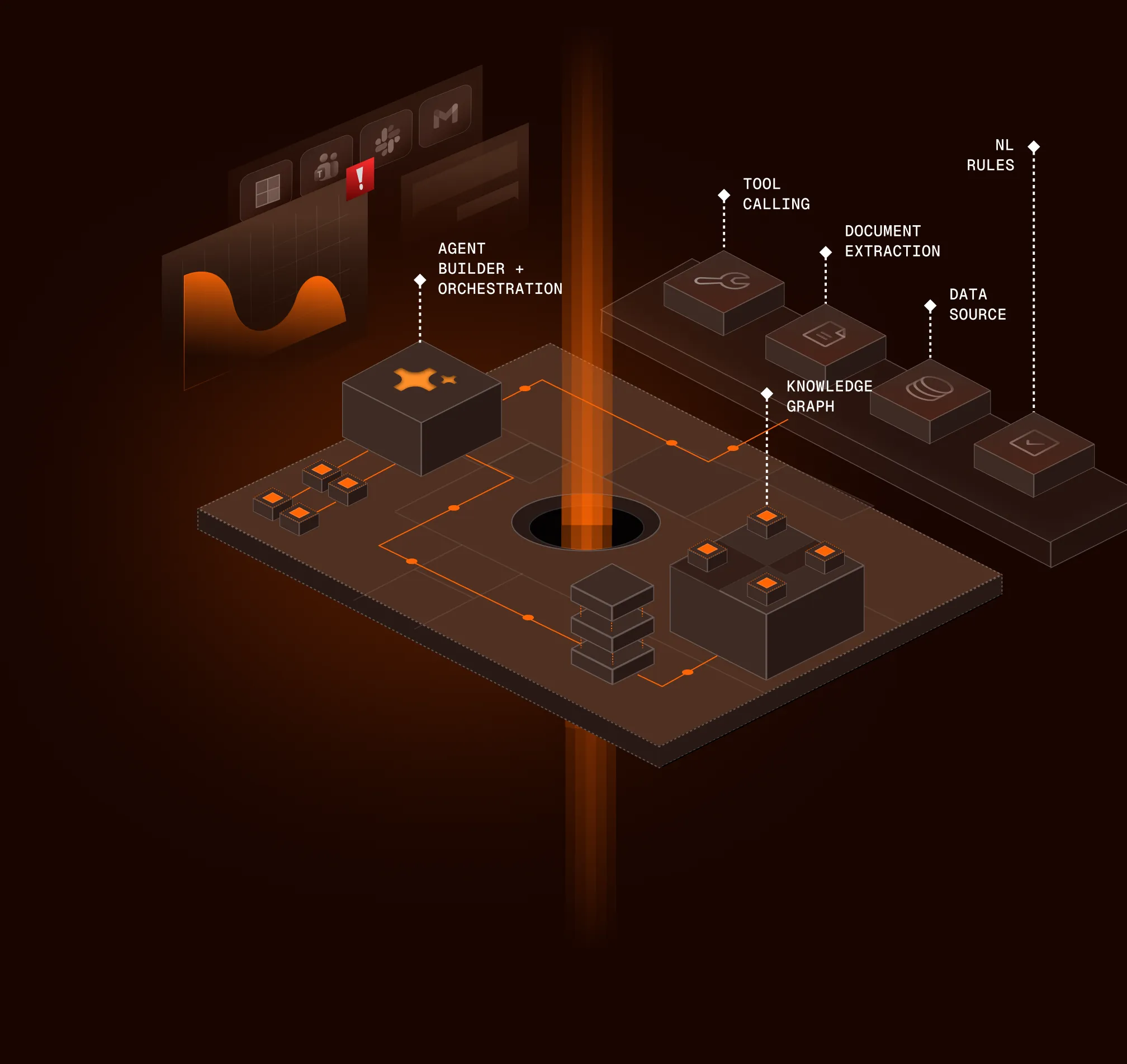
You define how far autonomy goes
Studio is where operators set rules in plain language - what auto-approves, what stops for a human, what gets escalated. You get visibility into what each AI Team did and why.



Decisions you can defend
Every action logs what data and rule it relied on - so finance and ops aren’t arguing from memory.
Know the “why.”
See the document, clause, or data point behind each outcome.
See performance, not black boxes.
Spot drift, compare outcomes, and adjust rules without a rebuild.
Autonomy on your terms.
Choose where agents run end-to-end and where a person must sign off.
Enterprise-ready from day one
Encryption in transit and at rest, role-based access, and audit trails designed for financial scrutiny.



Frequently Asked Questions
Have further questions and can’t find the answers?
Contact us
How does Freehand connect to our systems?
SAP, Oracle, Dynamics, JDE, NetSuite, plus EDI, API, SFTP, and common middleware. We meet you where your data is.
Do we need engineers to run it?
No. Studio is built for ops and finance; IT is typically involved only for initial integrations.
How do we trust the AI isn’t making things up?
Outputs are tied to verified records in your graph — contracts, shipments, invoices — not invented context.
How does it get smarter over time?
Resolved exceptions and your feedback feed back into the system so the next cycle is sharper.
See the platform on your own spend
We’ll walk through how AI Teams would interpret your contracts and invoices - and what recovery could look like.




