Decision Traces: The Data Layer Nobody Built Until Now

May 9, 2026
•
6
mins

Every enterprise has a knowledge graph. Almost none have the layer above it — the record of why decisions were made.
A knowledge graph organizes what your supply chain knows. It connects suppliers to contracts, contracts to rates, rates to invoices, invoices to payments. It makes relationships queryable. For most supply chain AI applications, this is described as the foundation for intelligent decision-making. It is necessary. It is not sufficient.
The knowledge graph answers questions about the current state of your supply chain. It cannot answer the question that matters most when an AI agent takes a decision that affects a carrier relationship or causes a financial adjustment: why. Why did the system approve this invoice when the rate exceeded the contracted rate by 2%? Why did it route this exception to operations rather than finance? Why did it accept a verbal amendment to a carrier contract that nobody entered into any system? A knowledge graph does not contain any of this. That data layer — the layer of decision reasoning — has to be built separately. Almost nobody has built it.
What decision traces contain
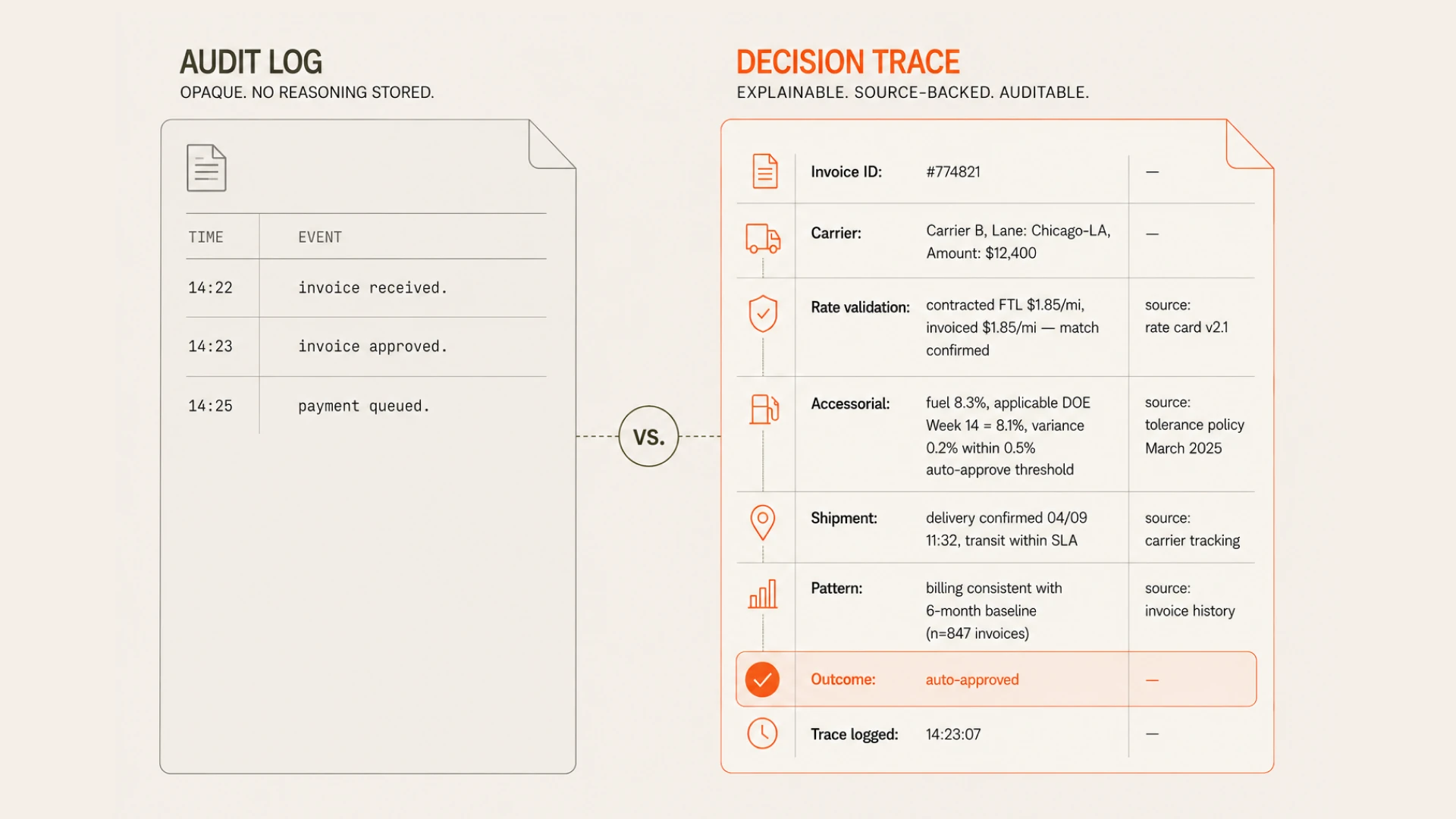
A decision trace is a structured record of the reasoning behind a specific decision. For a freight audit agent approving an invoice, the trace contains: the specific contracted rate retrieved from the knowledge graph, the shipment execution data that validated the charge conditions, the historical pattern that established whether a variance was within the organization's accepted tolerance, and the explicit reasoning step that produced the approve or dispute outcome. Each element is stored with a reference to its source — which record, which document, which prior decision established the context.
Decision traces differ from audit logs in a critical way. An audit log records what the system did: invoice received at 14:22, approved at 14:23, payment queued at 14:25. A decision trace records why: the fuel surcharge was approved because the invoiced rate of 8.3% matched the carrier's current fuel table (retrieved: rate card v2.4), was within the 0.5% auto-approve threshold (established: tolerance policy updated March 2025), and was consistent with this carrier's billing pattern over the prior six billing cycles (pattern baseline: established from 847 historical invoices on this lane).
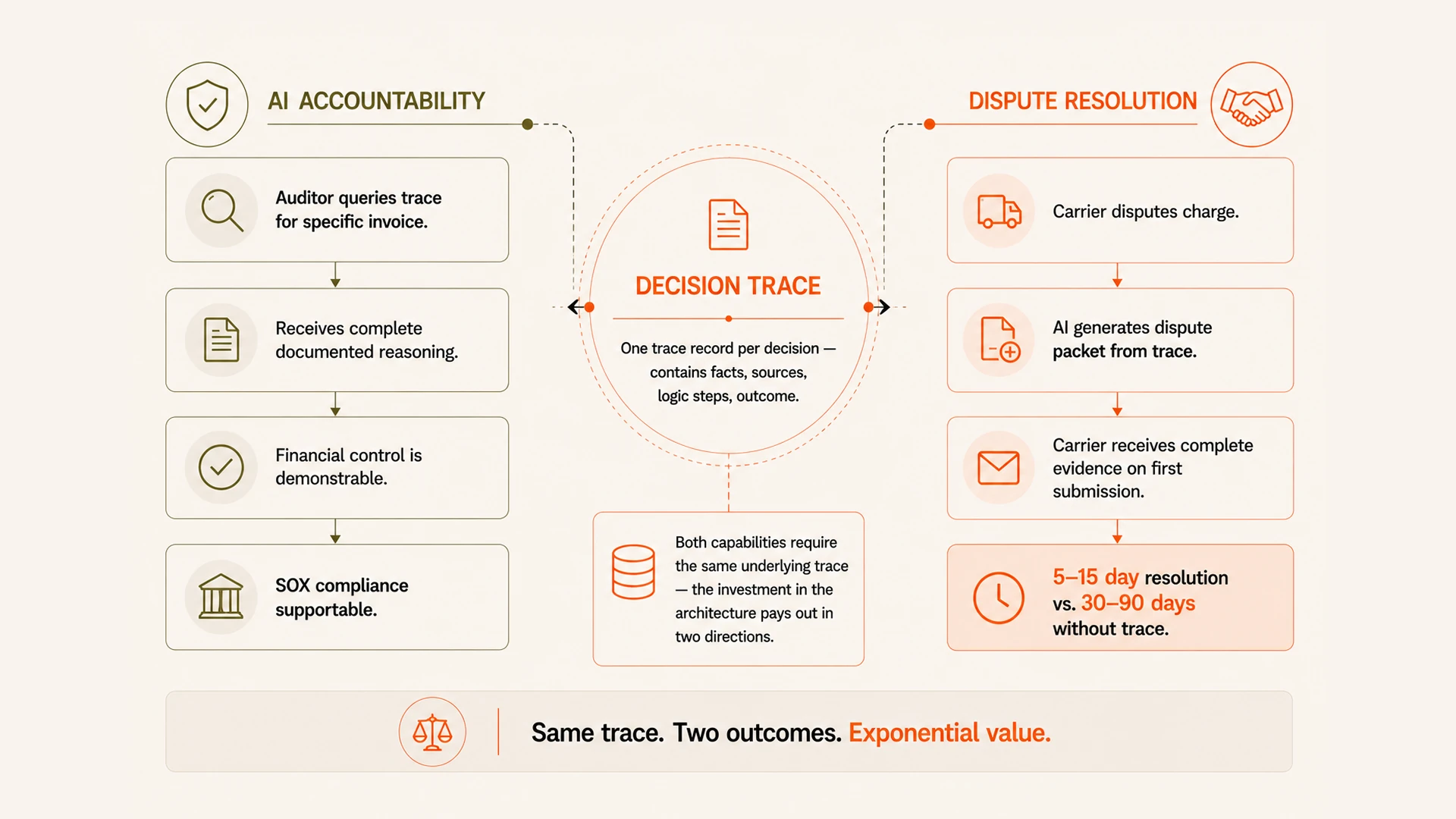
What decision traces enable that knowledge graphs cannot
The first thing decision traces enable is genuine AI accountability. When an external auditor reviews the freight audit function as a financial control, the question is not just whether the AI was accurate. It is whether the AI's decision logic is auditable — whether there is a traceable record of what facts were used, what logic was applied, and what would have produced a different outcome. A knowledge graph supports accuracy. A decision trace supports auditability.
The second thing decision traces enable is institutional learning. When a carrier disputes a decision generated by the AI agent, the dispute documentation is drawn directly from the decision trace — the contracted rate, the shipment data, the calculation. The carrier receives a dispute packet that is complete on first submission. There is no back-and-forth about what the shipper's position is. The trace is the position. Resolution times that run 30 to 90 days in traditional dispute processes compress to 5 to 15 days when the evidence is assembled automatically from the trace.
“A knowledge graph tells the AI what is true. A decision trace tells the organization why the AI decided. The second layer is what makes autonomous AI trustworthy in a regulated finance environment.”
Why it has not been built
The reason decision traces are absent from most enterprise AI deployments is that they require the traceability to be designed in from the start. A system that was built to produce decisions efficiently — to approve invoices, route exceptions, generate disputes — and then asked to explain those decisions afterward cannot produce a genuine trace. The trace has to be generated as part of the decision process, not reconstructed from the output.
This is an architecture choice made at the beginning of an AI deployment, not a feature that can be bolted on later. Organizations that are deploying AI now with the intent to add auditability later will find that the later never arrives in a satisfactory form. The decision that does not record its reasoning at the moment it is made cannot be explained after the fact. The accounting team that wants to understand why a $340,000 invoice was approved will not be satisfied with a model accuracy statistic.