How Duplicate Invoice Detection Actually Works at Scale

March 9, 2026
•
6
mins

PRO number matching catches one type of duplicate. Enterprise freight produces four. The difference is material.
Duplicate invoice detection sounds straightforward: find invoices submitted more than once and block the second payment. The challenge is in how 'more than once' manifests in practice. Enterprise freight generates duplicates in several distinct ways, and a detection system that handles one type while missing the others is catching the visible duplicates while the invisible ones accumulate.
The visible duplicate is the simplest case: a carrier submits the same invoice twice with the same invoice number. This is caught by any AP system with basic deduplication logic. It is also the rarest type of duplicate in enterprise freight. The more common patterns are structurally harder to detect.
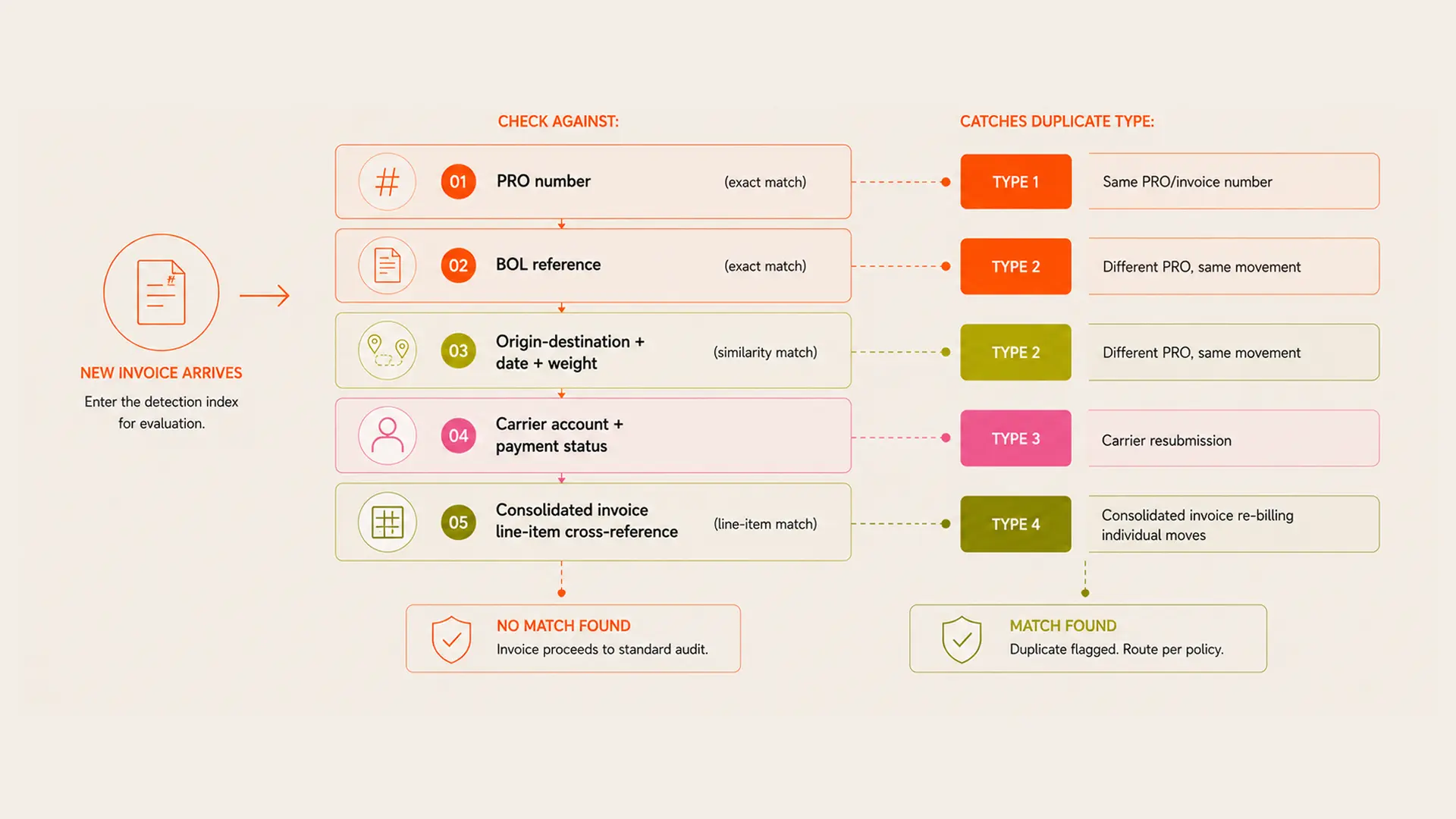
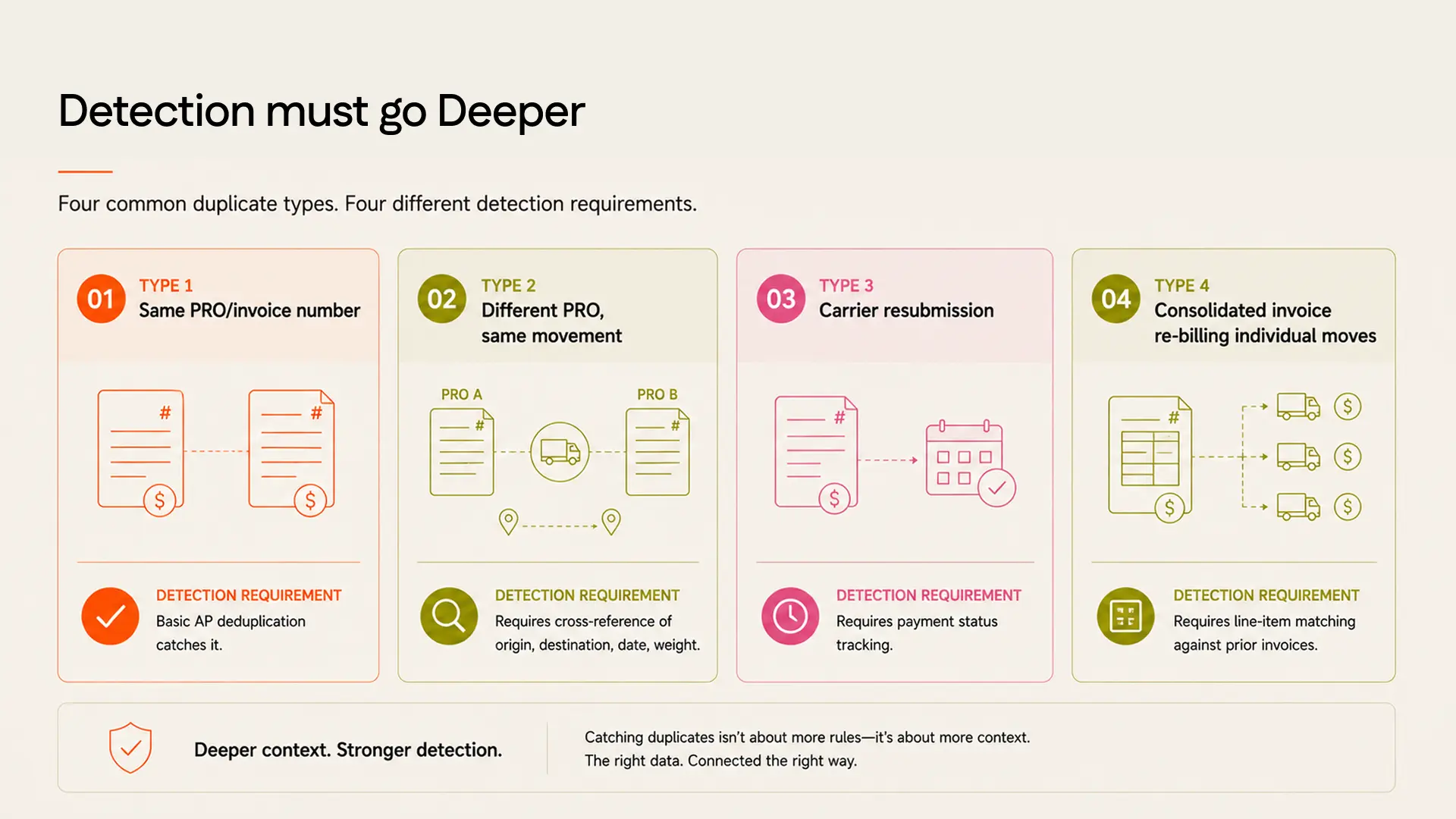
Four types of freight duplicate
The first type is PRO number variation. Carriers sometimes assign multiple PRO numbers to the same physical shipment movement, either due to system errors during carrier consolidation or legacy billing practices that split a multi-stop move into separate billing references. An invoice matching system looking for duplicate invoice numbers will miss this because the invoices carry different PRO numbers. Catching it requires cross-referencing shipment attributes: origin, destination, pickup date, service type, and weight, against the PRO reference to identify movements that were billed twice under different identifiers.
The second type is BOL reference mismatch. When a shipper's bill of lading number and the carrier's PRO number diverge in the carrier's billing system, invoices for the same shipment can appear under different reference numbers depending on which identifier the carrier used. A carrier audit that reconciles against BOL numbers will miss duplicates recorded under PRO numbers, and vice versa.
0.5–1.5% of enterprise freight invoices are duplicates — most of them invisible to PRO-number-only matching
Carrier resubmissions and the timing problem
The third duplicate type is the carrier resubmission. When a carrier's original invoice is disputed or delayed in the audit queue, the carrier may resubmit under a new invoice number. The resubmission is a legitimate business practice if the original was genuinely disputed. It is a duplicate if the original was merely delayed in the audit pipeline rather than actually contested.
Detecting resubmission duplicates requires awareness of the payment status of the original invoice. If the original was paid, the resubmission is a duplicate. If the original was disputed, the resubmission may be a corrected invoice. If the original is sitting in the audit queue unpaid, the resubmission is almost certainly a duplicate filed because the carrier's AP system flagged the outstanding balance. A detection system that does not track payment status cannot reliably distinguish between the three cases.
The consolidation problem
The fourth type is the most complex: consolidated invoices that include shipments already billed and paid at the individual level. Carriers that move from shipment-level invoicing to consolidated billing for a customer will sometimes include shipments in the consolidated invoice that were previously billed as individual invoices. The consolidated invoice does not carry duplicate reference numbers. It carries a new invoice number for a new billing format. The duplicates are buried in the line items.
“A carrier switching from shipment-level to consolidated billing has no systemic reason to know which moves were previously billed individually. The shipper's audit system does. Unless it checks.”
What comprehensive duplicate detection requires
Comprehensive duplicate detection requires a data architecture that maintains a persistent shipment history indexed by multiple attributes simultaneously: PRO number, BOL number, origin-destination pair, service date, carrier account, and weight. When a new invoice arrives, it is checked against this multi-attribute index rather than against a single identifier.
The lookup has to run probabilistically, not just on exact matches, because carrier billing systems frequently have data quality issues that produce near-duplicate records rather than exact duplicates. A shipment from Chicago to Atlanta on March 3 weighing 840 pounds may appear in two invoices as 'Chicago IL to Atlanta GA 840 lbs 03/03' and 'Chicago to Atlanta 840 lb 3/3.' An exact-match deduplication misses this. A similarity-based lookup catches it.
The payment and timing layer adds the final check: confirmed duplicates are blocked before payment, and post-payment duplicates trigger recovery workflows with credit memo tracking. The recovery workflow matters because post-payment duplicates that are identified but not actively tracked tend to get absorbed by the carrier rather than credited back.