The Context Gap: What Separates a Chatbot from an Agent

March 6, 2026
•
6
mins

The distance between a recommendation and a decision looks small in a diagram. In enterprise operations, it is years of infrastructure.
If you have been in a room where someone demonstrated a supply chain AI in the past two years, you have seen this: a natural language query, an intelligent-sounding response, a recommendation with supporting data. The demo is impressive. The limitation surfaces when you ask the system to act on what it just recommended.
Most supply chain AI deployments operate in the left half of a spectrum. On the left: systems that summarize, analyze, and recommend. On the right: systems that decide, act, and execute. The distance between them looks like a product feature gap. It is actually an infrastructure gap.
What knowledge graphs give you
Graph databases have existed for decades. A knowledge graph over supply chain data, connecting carriers to contracts to lanes to invoices to rates, is achievable with a competent data engineering team in a reasonable timeframe. Any LLM connected to a well-constructed knowledge graph can answer questions that used to require an analyst: what is our average freight cost on this lane, which carriers are performing below SLA this month, what is the spend trend on parcel.
This is genuinely useful. It is not the same as agentic capability. The gap between 'answer a question' and 'take a decision and execute against it' is not closed by connecting an LLM to a knowledge graph. It is the context gap: the infrastructure and plumbing required to give an AI system the decision-making context that allows it to act reliably rather than just reason well.
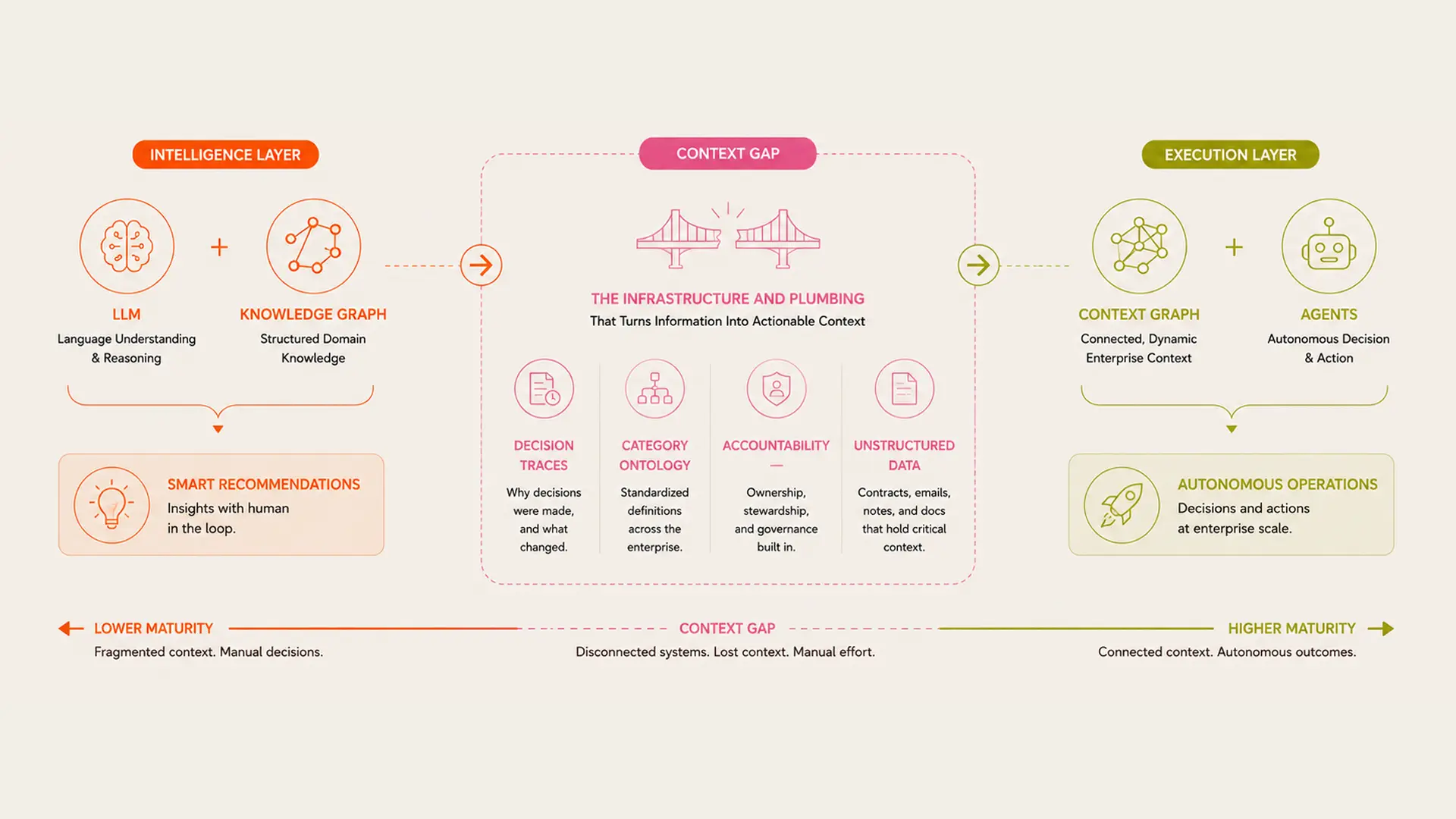
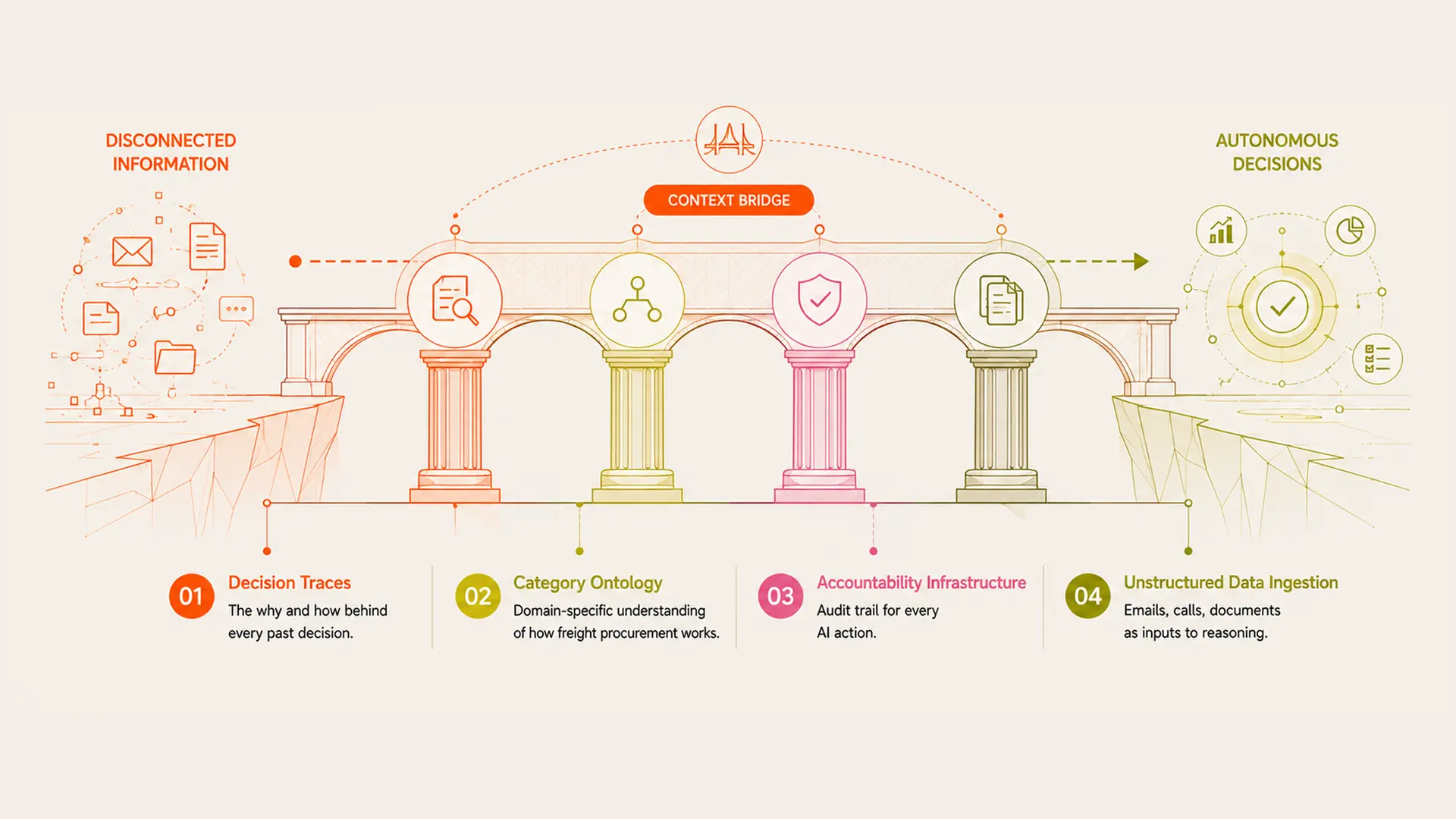
What the context gap contains
The context gap is not one thing. It is several things that need to be built and connected.
Decision traces: the record of how exceptions were resolved, why a rate was accepted, what the rationale was behind an approval that deviated from policy. These are not in the ERP. They are in emails and meeting notes and the memories of people who may have left.
Category-specific ontology: a semantic model of how freight procurement works that goes beyond generic entity relationships. One that understands that a fuel surcharge cap on a TL contract applies differently than the same cap on an LTL contract, that accessorial charges have carrier-specific trigger conditions, that exception approvals have relationship-specific tolerances that vary by carrier and lane history.
Accountability infrastructure: when an AI agent takes a decision, what is the audit trail? Which piece of context justified which action? The accountability layer is not a reporting feature. It is what makes autonomous action trustworthy in a regulated finance environment.
“A chatbot plus a database is not an agent. An agent is what happens when AI can access not just what was recorded but why decisions were made. That requires infrastructure most enterprises haven't built.”
Why this gap matters more in logistics than elsewhere
Logistics and freight payment is an unusually demanding context for AI agents because the decisions are financially material and the domain knowledge is highly specialized. A general-purpose AI agent making decisions about freight invoices without deep carrier billing knowledge, without exception history context, and without understanding of the relationship dynamics between a shipper and a specific carrier will produce errors that cost real money and damage carrier relationships.
The context graph architecture is the answer to this: building not just a data model but a domain-specific reasoning infrastructure that captures the institutional knowledge, the decision history, and the category-specific logic that allows an AI agent to act reliably in freight procurement rather than requiring human supervision on every non-standard case.
Crossing the chasm from the left side to the right side of that spectrum is what Freehand was built to do. The infrastructure work is not glamorous. The outcome is: AI that runs global freight operations without a human in the approval loop for 95 percent of the volume.